Drawdown-riski – ja mikä sen määrittää
2
forum
|
Uusin: Markku Kurtti—23.9.2021 - 17:45
Markku Kurtti
+68
Liittynyt:
4.12.2020
Viestejä:
9
Kirjoitin aikaisemmin, että hajauttaminen on negatiivisen hinnan lounas, koska se kasvattaa geometrista tuotto-odotusta eli tuottoa. Mutta hajauttamisen tärkein ominaisuus on tietysti riskin pienentäminen.
Tässä kirjoituksessa keskityn riskiin. Rahoitusteoria sanoo, että riski on tuottojen keskihajonta (volatiliteetti) eli tuoton epävarmuus. Mielestäni volatiliteetti on yksinkertainen ja hyvä riskin määritelmä. Usein kuitenkin kuulee, että lyhyen aikavälin heilunta ei ole relevantti riski, jos sijoitushorisontti on pitkä. Ja tottahan se on, että pitkällä aikavälillä volatiliteetti pienenee eli annualisoitu tuottojakauma kapenee. Näin mitaten riski pienenee. Historiallisesti laajasti hajauttavan osakesijoittajan tappion todennäköisyys on lähestynyt nollaa, kun tuotto on mitattu periodin lopussa ja sijoitushorisontti on kivunnut kymmenen vuoden paremmalle puolelle.
Lähes varma ja todennäköisesti suuri tuotto pitkällä aikavälillä kuulostaa houkuttelevalta. Onko pitkällä aikavälillä sijoittavalla siis riskiä ollenkaan? Mielestäni on paljonkin. Oikeassa elämässä hyvin harva pystyy sijoittamaan merkittävän summan kymmeneksi tai kymmeniksi vuosiksi, pistämään silmät kiinni markkinoilta ja elämän muuttuvilta rahatarpeilta, ja lopulta kuittaamaan voitot. Pitkä aikaväli koostuu peräkkäisistä lyhyistä aikaväleistä, joista jokaisesta on selvittävä tai pitkä aikaväli lakkaa olemasta. Päästäkseen perille on selvittävä matkasta.
Käytännössä riski liittyy juuri matkantekoon. Riski on matkan kuopat, niiden määrä ja etenkin niiden syvyys. Kun matka alkaa meren pinnan tasolta ja määränpää on vuoren huipulla, niin pahimmalta tuntuu mennä pinnan alle. Happi alkaa loppua ja paine kasvaa mitä syvemmälle sukelletaan.
Edellä kuvattua riskiä voisi mitata esimerkiksi pinnan alle johtavien sukellusten maksimisyvyyksien todennäköisyyksillä. Tai kätevästi yhdellä numerolla: sukelluksen maksimisyvyyden odotusarvolla.
Onko tällaisia kvantitatiivisia mittareita olemassa? Näyttäisi, että on. Käytän lähteenä Ed Thorpen ehtymätöntä tuotantoa. Thorp antaa mielenkiintoisen kaavan 7.13, joka määrittää todennäköisyyden sille, että pääoman arvon suhde alkupääomaan alittaa valitun raja-arvon x (0 < x < 1 eli tappiot välillä 100% ja 0%) jollakin ajan hetkellä:
Prob(V(t,c)/V0 <= x for some t) = x^(2/c – 1)
V(t, c) on pääoman arvo ajan hetkellä t ja Kelly fraktiolla c (kaava toimii välillä 0 < c < 2). V0 on alkupääoman arvo (ajanhetkellä t = 0). Kaava olettaa, että aika menee nollasta äärettömään ja ilmaisee todennäköisyyden tapahtumalle, että jollakin ajanhetkellä ollaan tappiolla vähintään raja-arvon x verran. Kyseessä on siis kertymäfunktio (CDF).
Kyseessä on siis Kelly kriteeriin liittyvä funktio. Miten sitä käytetään sijoittamisessa? Tätä olen tutkinut gradussani ja sieltä oleellinen kaava on kaava 72:
c = fs/SR
Kelly-fraktio c on siis sijoitusasteen (f), keskihajonnan eli volatiliteetin (s) ja Sharpe ration (SR) funktio.
Näin ollen voimme kirjoittaa Thorpen kaavan sijoitusmaailmasta tutuilla muuttujilla:
Prob(Ve(t,c)/V0 <= x for some t) = x^(2SR/fs – 1)
Nyt, koska Sharpe ratio ilmaisee riskittömän koron ylittävän tuoton (excess return) suhteen volatiliteettiin, tämä kaava tarkalleen ottaen määrittää todennäköisyyden sille, että pääoman arvon suhde riskittömän koron kerryttämään pääomaan alittaa valitun raja-arvon x jollakin ajan hetkellä. Portfolion arvolle V on ilmestynyt alaindeksi e (excess) joka viittaa riskittömän koron ylittävään portfolion arvoon. Viitaten aikaisempaan merenpinnan tasolta lähtevään matkaan, meren pinta nousee (tai laskee negatiivisilla koroilla) nyt riskittömän koron portfolion kasvun tahdissa.
Näin nollakorkojen aikana voimme käytännössä tulkita Ve/V0 edelleen (koska riskittömän koron portfolion arvo ei kasva) tarkoittavan kertyneen pääoman suhdetta alkupääomaan. Meren pinta pysyy siis näissä olosuhteissa suunnilleen vakiotasolla.
Kaava antaa meille siis käytännössä pitkän sijoitushorisontin maksimi drawdownin (portfolion nykyarvosta) todennäköisyyden. Yleisimminhän drawdown mitataan portfolion huippuarvosta, mutta nyt keskitymme drawdowniin mitattuna portfolion nykyarvosta. Tämä mittari on kätevä, kun halutaan ymmärtää millainen arvonlaskuriski portfolion nykyarvoon kohdistuu pitkällä aikavälillä.
Koska Thorpen tarjoama kaava on kertymäfunktio, voimme derivoida sen ja saada tiheysfunktion (PDF) ja edelleen integroida x*PDF, mikä antaa meille odotusarvon.
Jollakin tulevalla ajanhetkellä (kun t --> inf) tapahtuvan maksimi drawdownin odotusarvo eli drawdown-riski on mainittujen laskutoimitusten jälkeen yksinkertaisesti:
E[max(DD_RF)] = c/2 = fs/(2SR)
DD_RF tarkoittaa ”DrawDown from Risk Free portfolio value”. Drawdown-riskin kaava on yksinkertainen, lineaarinen ja sisältää vain kolme tuttua komponenttia: sijoitusaste, volatiliteetti ja Sharpe ratio.
Kaavasta on helppo tulkita: Maksimoi Shape ratio ja säädä haluamasi riskitaso (sijoitusaste*volatiliteetti). Kuulostaa portfolioteorian oppitunnilta. Portfolioteoria ei (ilman hyötyfunktioita) kuitenkaan ota kantaa maksimisijoitusasteeseen. Oikeassa elämässä ihmiset kuitenkin välittävät geometrisista tuotoista (aritmeettisten sijaan), jolloin järjellinen maksimisijoitusaste f* (tämä on ns. Full Kelly sijoitusaste, joka johtaa geometrisen keskiarvotuoton maksimiin) saadaan kun c = 1 eli f* = SR/s. Tämän pisteen ylittäminen johtaa pienevään geometriseen tuotto-odotukseen, mutta edelleen kasvavaan riskiin. Tästä saadaankin mielenkiintoinen vaihtoehtoinen tulkinta Sharpe ratiolle: SR on portfolion volatiliteetti sijoitusasteella f*, jolla geometrinen tuotto-odotus maksimoituu. SR on siis yläraja geometrisista tuotoista välittävän sijoittajan portfolion volatiliteetille, geometrisen efficient frontierin päätepiste.
Oleellinen huomio drawdown-riskistä on myös, että koska Sharpe ratio sisältää tuotto-odotuksen m (SR = (m – r)/s), niin drawdown-riski on myös tuotto-odotuksen funktio. On siis mahdollista, että portfolion A keskihajonta on suurempi kuin portfolion B (eli riski volatiliteetilla mitattuna on suurempi), mutta portfolion A drawdown-riski on B:n vastaavaa pienempi. Tämä on mahdollista, mikäli portfoliolla A on riittävän paljon suurempi tuotto-odotus (ja Sharpe ratio). Kuitenkin keskihajonta s vaikuttaa kaavassa käytännössä neliöitynä eli sen voidaan ajatella dominoivan lopputulosta tuotto-odotuksen sijaan.
Samoin on huomion arvoista, että koska arvostustasot vaikuttavat tuotto-odotukseen ja siten Sharpe ratio -odotukseen, niin drawdown-riski on arvostustasojen funktio. Korkealla arvostustasolla eteenpäin katsova Sharpe on alempi ja drawdown-riski siten suurempi. Ajoittamalla markkinaa arvostustasojen perusteella on vaikea tehdä ylituottoa, mutta drawdown-riskiä sillä voinee alentaa.
Simulaatiot:
Toimivatko nämä kaavat käytännössä? Yritän selvittää tätä kahdella tapaa: simuloimalla ja empiirisestä datasta. Simulaation suurin etu empiiriseen dataan on se, että vaihtoehtoisia historioita voidaan luoda tuhansia ja historioiden pituus voi olla teoriassa mitä vain. Rajoittava tekijä on simulointiaika. Simulaatioon verrattuna empiirinen data on auttamattoman lyhyt ja meillä on vain yksi (n = 1) realisoitunut historia.
Aloitetaan simulaatioista ja todennäköisyyskaavasta. Simuloin päivätuottoja, koska kuukausituotoilla merkittävä osa drawdownista jää piiloon, kun syvimmästä kuopasta noustaan ennen kuukauden päättymistä. Päivätuototkaan eivät vastaa kaavan teoreettisia äärettömän lyhyitä tuottoja, mutta ne ovat riittävän lähellä. Toinen merkittävä valinta on käytetty päivätuottojakauma. Yleensä käytetään normaalijakautuneita tuottoja, mutta todellisuudessa osakemarkkinan päivätuottot ovat paksuhäntäisiä eivätkä siten vastaa normaalijakaumaa. Simuloin sekä normaalijakautuneilla, että Laplace-jakautuneilla päivätuotoilla. Laplace jakauman muoto vastaa erittäin lähelle empiiristen päivätuottojen jakauman muotoa. Mielenkiintoinen havainto on, että simulaation tulokset ovat identtiset riippumatta valitusta tuottojakaumasta. Kaavat siis eivät ole herkkiä tuottojakauman muodolle.
Simuloin 1, 5, 10, 20, 40, 100 ja 1000 vuotta pitkät sijoitushorisontit ja luon 80 000 (1v) – 10 000 (1000v) kpl riippumattomia rinnakkaisia tuottohistorioita. Kaavat olettavat äärettömän pitkän sijoitushorisontin, joten haluan tutkia miten ne toimivat realistisella pitkällä aikavälillä. 1000v pitkän periodin tarkoitus on testata konvergoituuko tulos lähelle kaavan ennustamaa arvoa. Oletan 252 treidauspäivää per vuosi, jolloin esim. 1000v ja 10 000 historiaa tarkoittaa 2.52 miljardia päivätuottoa per simulaatio. Kun tuottohistoriadata on luotu, poimin jokaiselle simuloidulle historialle sen maksimi drawdownin portfolion alkuarvosta. Näistä maksimi drawdowneista lasken sitten todennäköisyydet ja vertaan niitä kaavan antamiin teoreettisiin todennäköisyyksiin.
Olen poiminut päivätuottojen parametrit (”Mkt-RF” eli keskiarvo excess tuotto ja sen keskihajonta) Kenneth Frenchin USAn datasta aikavälille Jul/1926 – Jun/2021 eli tasan 95 vuoden ajalta. Keskiarvo vuosittaiselle (aritmeettiselle) excess keskiarvotuotolle on 8.09% ja keskihajonta 17.51%. Geometrinen vuosittainen excess keskiarvotuotto on 6.56% ja Sharpe ratio 0.4618. Teoreettinen full Kelly sijoitusaste f* = 2.64. Lukemat ovat continuous compounding muodossa.
Oletus on, että lyhyellä aikavälillä kaava ei pidä paikkaansa, onhan kaavan aikahorisontti äärettömän pitkä. Alla näkyy kuva yhden vuoden sijoitushorisontille. Kuvassa on simuloitu käyrät eri Kelly-fraktioille c = 0.25, 0.5, 1, 1.5 ja 1.75. Halutut Kelly-fraktiot saadaan kertomalla luodut päivä excess-tuottot (joiden f = 1) sopivalla sijoitusasteella f. Katkoviiva näyttää kaavan ennustamat todennnäisyyskertymät, jotka muodostavat sipulin muotoisen symmetrisen kuvion. Vuoden periodilla simuloidut käyrät ovat oikeassa järjestyksessä, mutta kaukana kaavan ennusteista.
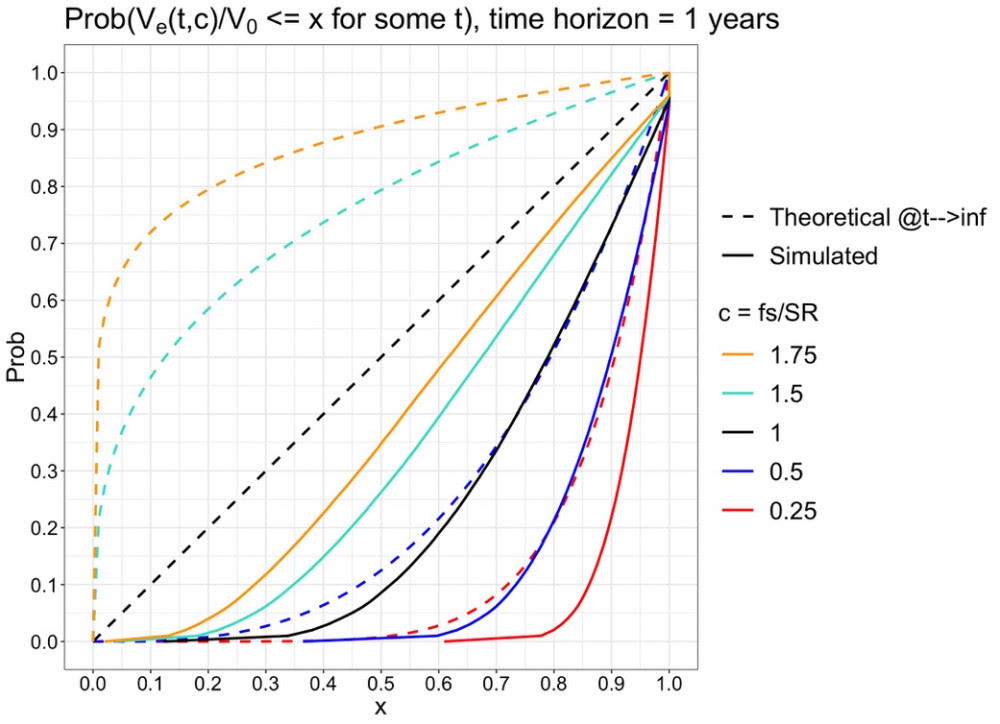
Kymmenen vuoden periodilla simuloidut käyrät alkavat selvästi lähestyä teoreettisia ennusteitaan, kun Kelly-fraktio c on pienempi kuin yksi (relevantti väli on 0 < c <= 1, koska geometrinen tuotto-odotus alkaa laskea, kun c > 1). 20 vuoden periodilla todennäköisyydet ovat jo lähellä ennusteitaan relevanteilla c arvoilla.
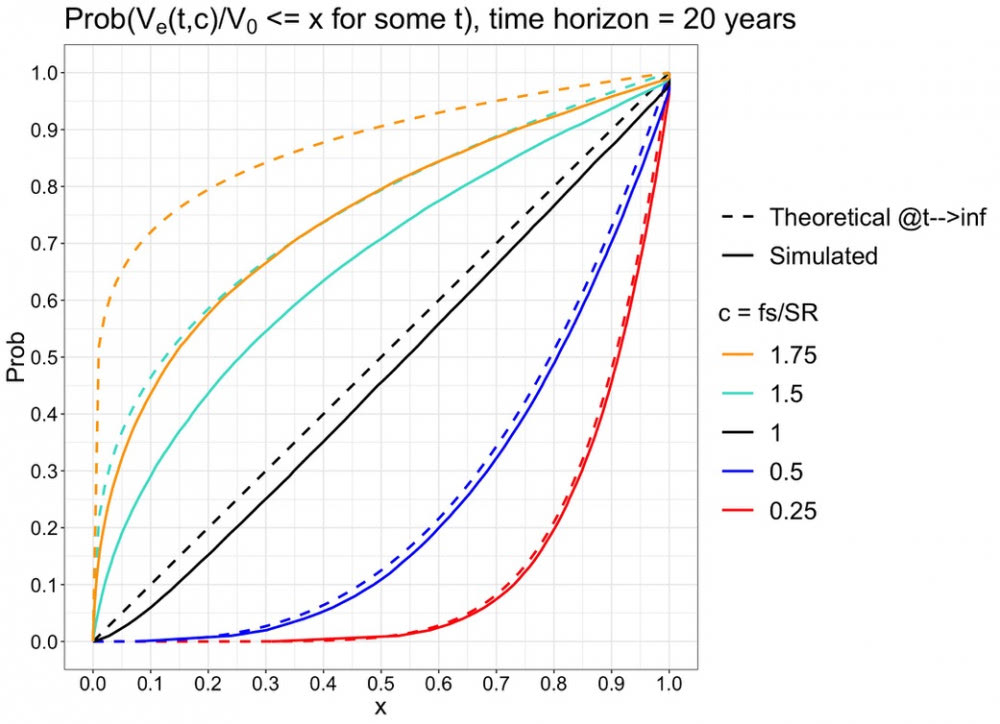
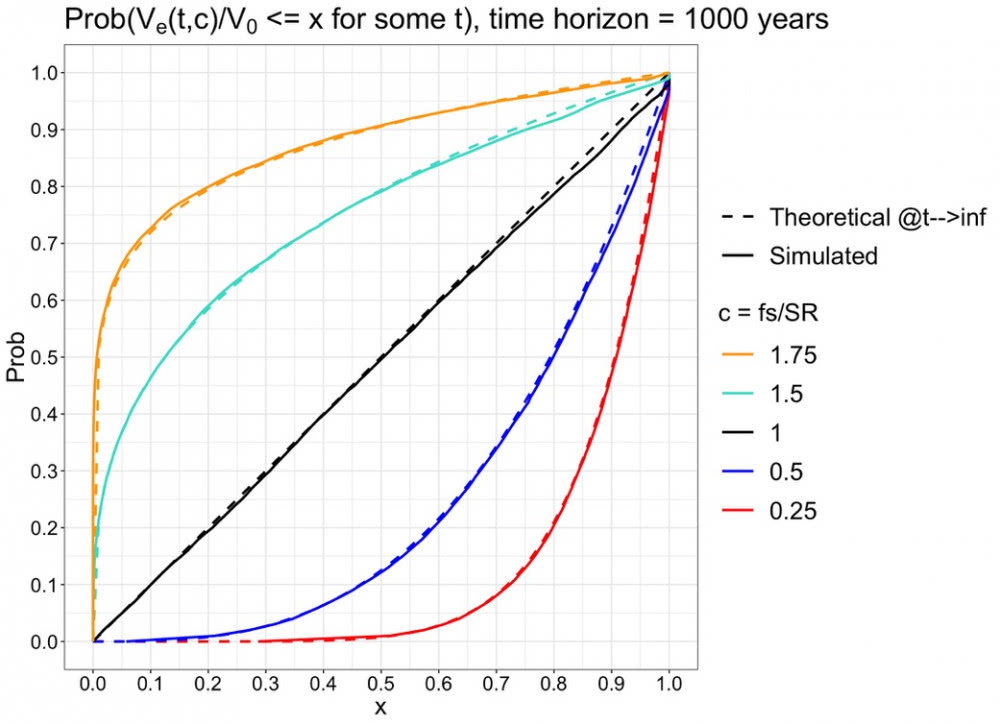
1000v simulaatio näyttää, että simulaatio toteuttaa teoreettiset ennusteet myös isoilla c-arvoilla, kun aika vaan on riittävän pitkä.
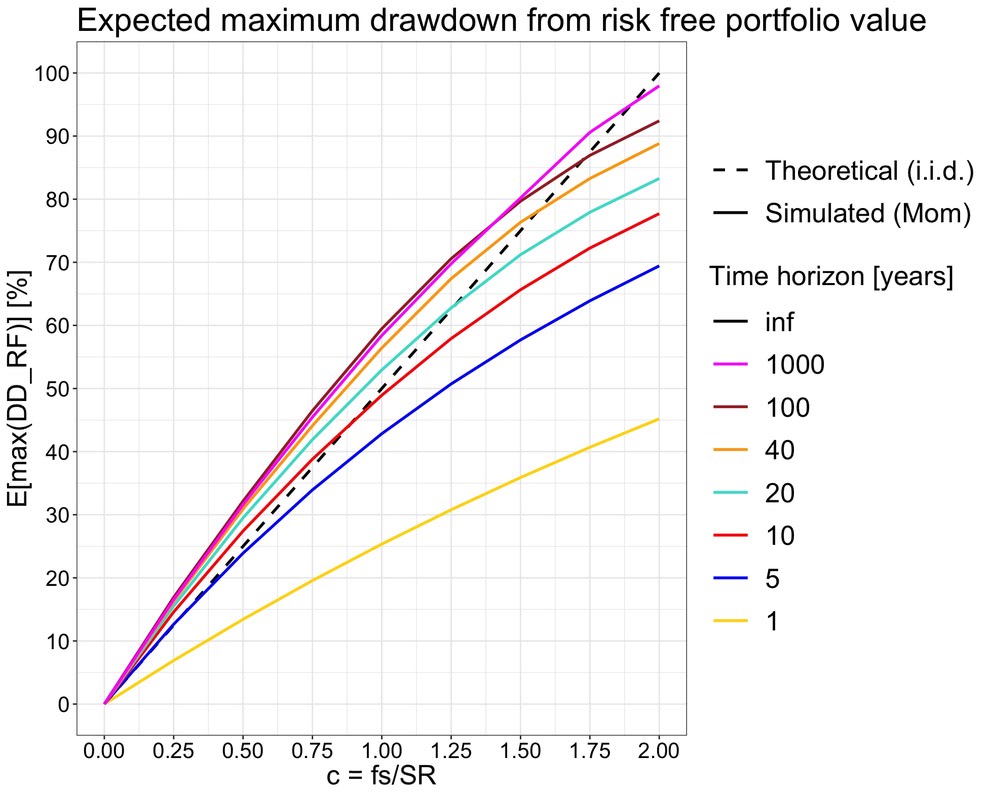
Keräsin simulaatioista myös maksimi drawdownien keskiarvot ja vertasin niitä teoreettiseen odotusarvoon. Alla olevasta kuvasta nähdään, että keskiarvo lähestyy teoreettista odotusarvoaan, kun sijoitusaikahorisontti pitenee. Full Kelly sijoitusasteella (c = 1) maksimi drawdownin odotusarvo on 50%. Kun c lähestyy arvoa 2 (jolloin geometrisen tuoton odotusarvo on riskittömän koron tuotto), drawdownin odotusarvo lähestyy 100%. Toisin sanoen: kun äärettömän pitkään sijoitat erittäin volatiililla porfolioliolla nolla tuotto-odotuksella, niin jossakin matkan varrella portfolion arvo lähestyy nollaa 100% todennäköisyydellä.
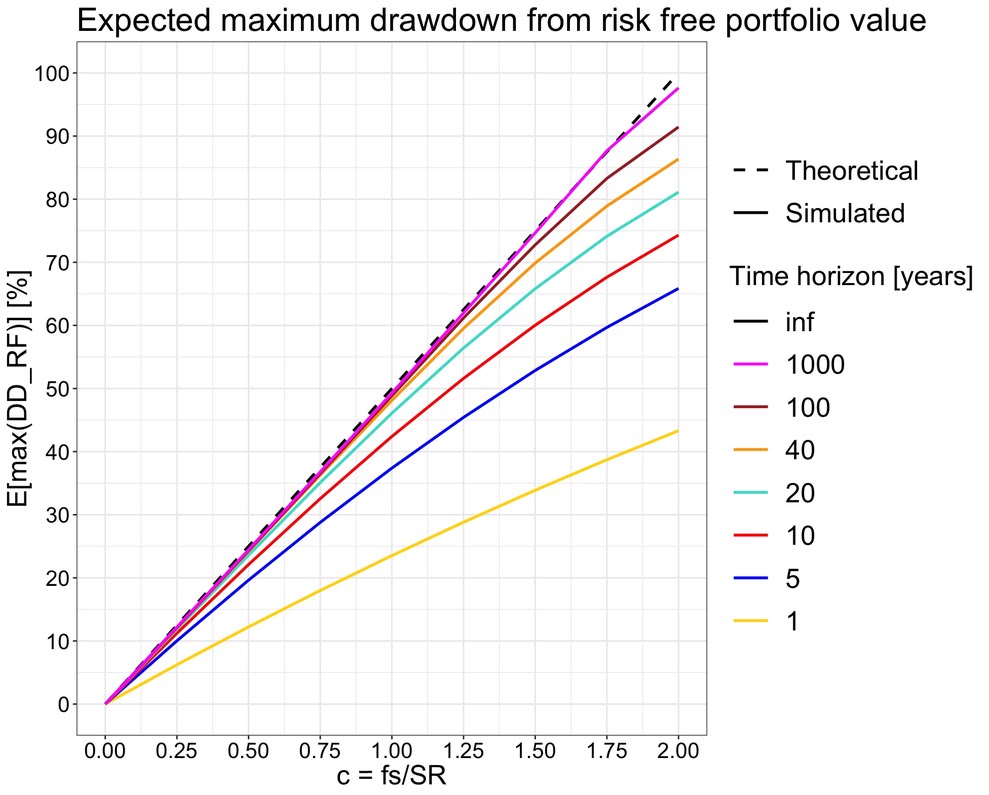
Kuvasta nähdään myös, että (relevantilla välillä 0 < c <= 1) 20 vuoden aikahorisontilla teoreettinen odotusarvo kuvaa jo erittäin tarkasti simuloidun lopputuloksen. Teoreettinen maksimi drawdownin odotustarvon kaava näyttää siis olevan hyvä approksimaatio myös realistisilla pitkillä sijoitushorisonteilla (ei pelkästään äärettömän pitkällä aikavälillä). Käyrät konvergoituvat nopeammin suuremmalla ja hitaammin pienemmällä tuotto-odotuksella. Tässä esitetyt simulaatiot käyttävät historiallisen osakedatan parametreja ja konvergoitumisnopeus edustaa sitä mitä voimme karkeasti odottaa osakemarkkinatuotoilta.
Simulaatiot siis näyttävät toteuttavan kaavojen ennustukset ja tämä tapahtuu käytännössä, kun sijoitushorisontti on kymmenen tai kymmeniä vuosia. Entä empiirinen data, totteleeko se kaavoja? Empiirinen data on ongelmallista etenkin, kun tarkastellaan pitkän aikavälin ilmiöitä. Dataa on yksinkertaisesti liian vähän. On kuitenkin ainakin yksi keino tutkia kyseistä maksimi drawdown todennäköisyyttä ja sen odotusarvoa: liukuvat ikkunat yli ajan. Maksimi drawdown on voimaakkaasti riippuvainen periodin aloitushetkestä. Jos aloitetaan tarkastelu juuri ennen 30-luvun isoa romahdusta, saadaan todella rumat lukemat. Toisaalta romahduksen pohjalta aloittaminen antaa paljon ruusuisemman kuvan. Ajoin liukuvalla ikkunalla kaikki mahdolliset aloituspäivät 1, 5, 10 ja 20 vuoden periodeille. Vuoden mittaiselle ikkunalle saadaan kelvolliset 95 riippumatonta periodia, mutta 20 vuoden ikkunalla riippumattomia periodeja on vain vajaa viisi.
Liukuvan ikkunan empiirisiä tuloksia tarkastellessa tuli nopeasti selväksi, että ne ovat hyvin saman suuntaiset kuin simuloidut tulokset, mutta jostakin syystä käyrät eivät ole yhtä lineaarisia. Tämä ero näyttäisi johtuvan siitä, että teoreettinen kaava (ja alkuperäinen simulaatio) olettaa riippumattomat tuotot (independent and identically distributed eli i.i.d.), mutta oikean elämän tuotot tunnetusti eivät ole täysin korreloimattomia aikasarjassa. Oikeassa elämässä tuottoihin vaikuttaa momentum (time series momentum) eli trendi. Lähimenneisyyden liike tuppaa keskimäärin jatkumaan samaan suuntaan. Halusin tutkia asiaa hieman lisää ja tein köyhän miehen momentum simulaattorin. Momentum simulaattorissa yksinkertaisesti luodaan aluksi i.i.d. tuotot ja jälkikäsittelyssä lisätään momentum lisäämällä realisoituneeseen päivätuottoon aritmeettisten päivätuottojen keskiarvo, jos edellisen 6kk keskiarvotuotto on yli odotusarvon ja vähentämällä vastaava, mikäli on jääty alle keskituoton. Tämä ei tietysti täysin vastaa oikeaa momentum-ilmiötä, mutta vaikutuksen pitäisi olla saman tyyppinen.
Alla olevissa kuvissa nähdään momentum simulaattorin käyrät verrattuna teoreettisiin i.i.d käyriin. Käyrät ovat hieman vaappuvia johtuen raskaammasta simulaatiosta ja siten huomattavasti pienemmästä datamäärästä verrattuna i.i.d. simulointeihin.
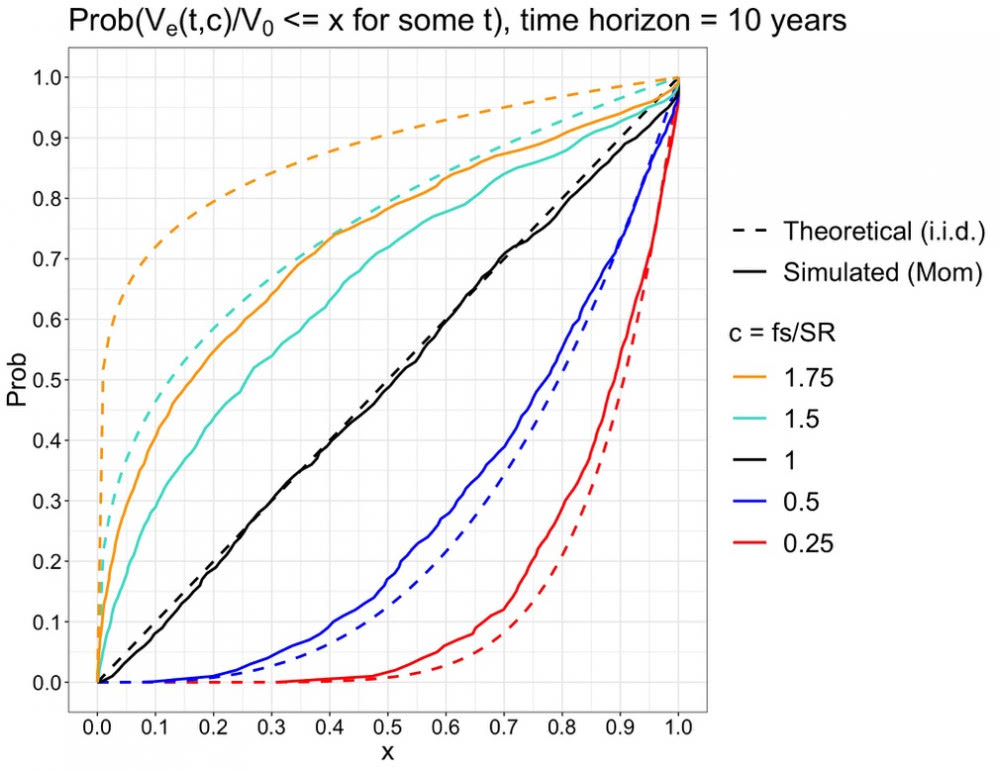
Jo kymmenen vuoden periodilla nähdään, että momentum simulaattorin käyrät korostavat isojen drawdownien todennäköisyyttä verrattuna teoreettisiin i.i.d. perustaisiin ennusteisiin. Suuret drawdownit ovat siis todennäköisempiä, kun meillä on momentumia.
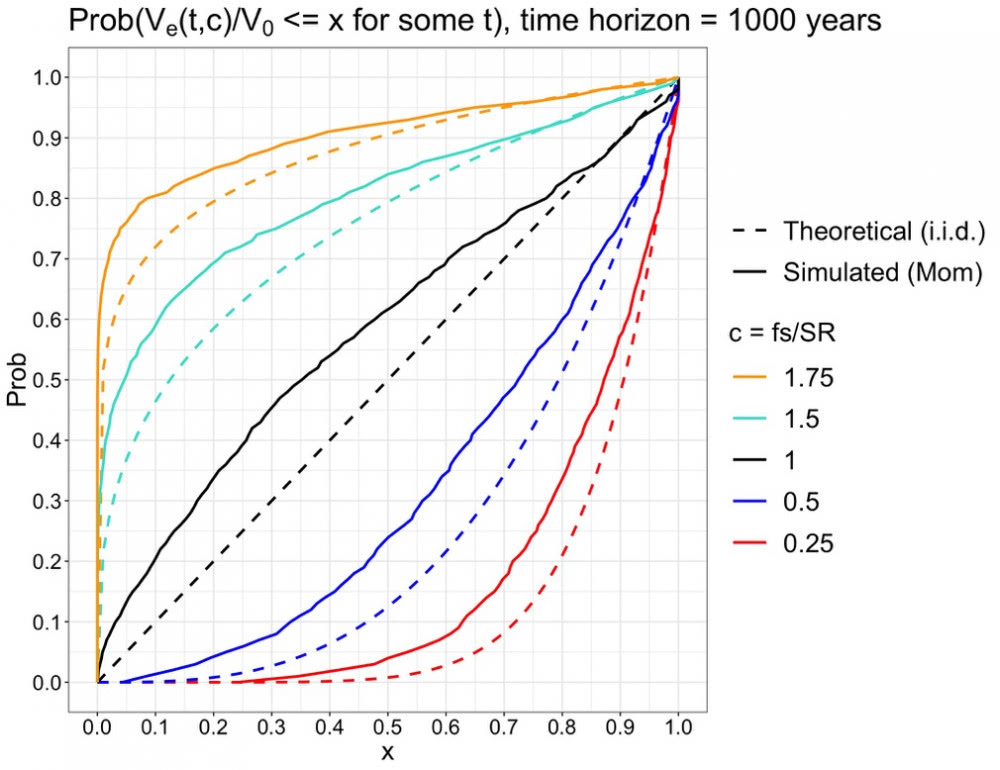
1000 vuoden periodilla näemme, että momentum korostaa suurien drawdownien todennäköisyyttä kaikilla Kelly-fraktioilla ja i.i.d. perustainen ennuste on aliarvio. Kelly-fraktioiden väliset suhteelliset erot pysyvät kuitenkin suunnilleen saman suuruisina kuin teoreettisessa i.i.d. mallissa.
Odotusarvokuvasta näemme, miten maksimi drawdownin odotusarvo ei ole lineaarinen, kuten kaavan antama odotusarvo ja i.i.d simuloidut käyrät, vaan hieman kaareva.
Empiirisen datan tulokset:
Sitten ne empiirisen datan tulokset liukuvalla ikkunalla. Alla olevasta kuvasta näemme, että odotusarvokäyrät muistuttavat muodoltaan kovasti momentum-simulaation käyriä. Samoin näemme, että koska momentum (tai muu aikasarjan korrelaatio) tekee maksimi drawdowneista syvempiä kuin i.i.d. kaava ennustaa, niin jo kymmenen vuoden periodi on lähellä (tai yleensä jopa hieman pahempi) teoreettista käyrää relevantilla välillä 0 < c <= 1. Empiirinen 10 vuotta näyttäisi siis olevan riittävän pitkä aikahorisontti, jotta teoreettista maksimi drawdownin odotustarvoa voi pitää kohtuullisen tarkkana approksimaationa.
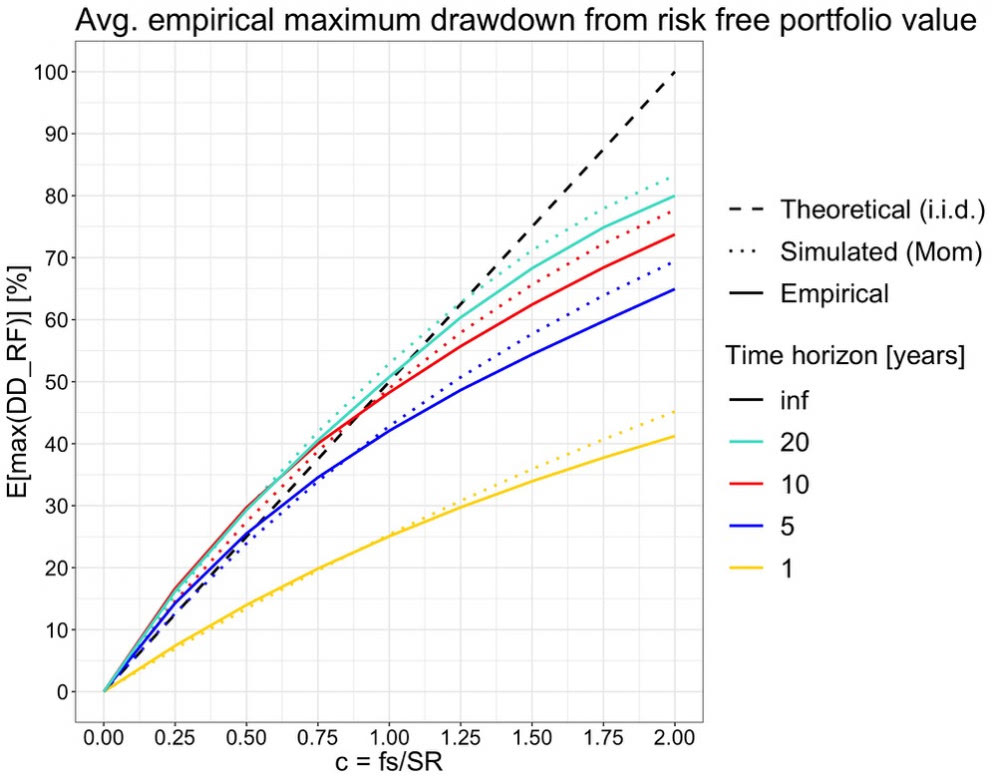
Aikasarjan korrelaatio (kuten momentum ilmiö) näyttäisi siis selittävän empriirisen datan käyrien eron verrattuna teoreettisiin käyriin. Voimme testata tätä vielä sekoittamalla satunnaisesti (suffled data seuraavassa kuvassa) empriirisen datan päivätuotot, jolloin momentum häviää datasta. Alla olevassa kuvassa olen sekoittanut empiirisen datan 500 kertaa jokaisessa pisteessä ja piirtänyt empriirisen datan noiden 500 sekoitetun tuloksen keskiarvona. Todellakin, sekoitettu empiirinen data vastaa hyvin tarkasti i.i.d. simuloitua dataa. Tämä näyttää meille hyvin kuinka merkittävä vaikutus aikasarjan korrelaatiolla (kuten momentumilla) eli tuottojen esiintymisjärjestyksellä on maksimi drawdowniin. I.i.d. simulaatiot (joita käytetään yleisesti) ovat sokeita tälle ilmiölle. Time series momentum eli trend following strategiat voivat tämän perusteella potentiaalisesti pienentää portfolion drawdown-riskiä ja parantaa riskikorjattua tuottoa.
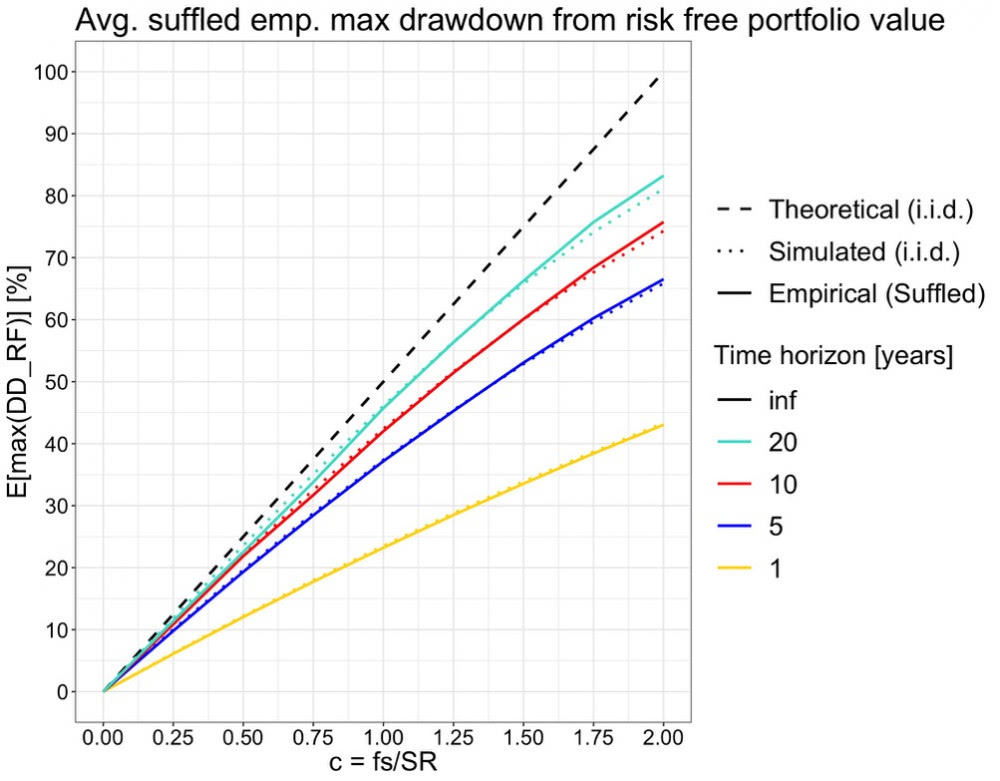
Riski & Tuotto:
Seuraavaksi tarkastelen vielä riskiä ja tuottoa samassa kuvassa. Tuotoksi valitsen pitkän aikavälin korkoa korolle -sijoittajia kiinnostavan riskittömän koron ylittävän geometrisen keskiarvotuoton (continuous compounding muodossa). Riskiksi valitsen tässä kirjoituksessa käsitellyn maksimi drawdown-riskin. Piirrän kuvaan sekä teoreettiset että empiiriset käyrät. Empiirinen riskittömän koron ylittävä geometrinen keskiarvotuotto on laskettu koko 95 vuoden historian ajalta, kun maksimi drawdownin odotusarvo on laskettu 10 vuoden periodilta (käyttäen liukuvaa aloituspäivää ja 10v ikkunaa läpi empiirisen datan).
Alla olevasta kuvasta näemme, että geometrinen empiirinen keskituotto vastaa hyvin tarkasti teoreettista arvoa. Toki tuottokäyrät eivät huomioi kuluja ja esimerkiksi olettavat, että sijoituslainaa saa riskittömän koron hinnalla. Todellinen tuotto siis olisi ollut alempi, mutta käyrän muoto ja se että käyrällä on maksimi on hyvä tiedostaa. Pieni käyrien välinen ero suurella sijoitusasteella selittyy rebalansointitaajuudella. Teoreettinen kaava olettaa äärettömän tiheän rebalansoinnin takaisin tavoitesijoitusasteeseen, kun empiirisellä datalla sijoitusaste rebalansoidaan päivittäin. Myös empiirinen riskikäyrä seuraa teoreettista käyrää hyvinkin tarkasti korkoa korolle -sijoittajalle relevantilla välillä 0 < c <= 1 eli 0 < f <= 2.64. Empiirinen riski on tyypillisesti vielä hieman suurempi kuin teoreettinen käyrä ennustaa.
Kuvasta näemme, miten 100% (f = 1) sijoitusasteella sijoittajan portfolio on kohdannut keskimäärin vajaan 25% maksimi drawdownin riskittömän koron portfoliosta. Vivutettaessa (teoreettisesti riskittömän koron hinnalla) 100% tasolta 200% sijoitusasteelle, keskimääräinen geometrinen tuotto on kasvanut vajaat 3.5%-yksikköä kun keskimääräinen maksimi drawdown on kasvanut yli 15%-yksikköä reilun 40% tasolle. Edelleen vivutettaessa 200% tasolta 300% sijoitusasteelle, tuotto on pysynyt käytännössä vakiona (300% sijoitusaste on yli full Kelly -pisteen eli tuotto on laskeva) samalla kun keskimääräinen maksimi drawdown on noussut yli 10%-yksikköä noin 52% tasolle. Vivuttamalla on (ainakin paperilla) siis ollut tiettyyn (full Kelly) rajaan saakka mahdollista tehdä suurempaa tuottoa, mutta jatkuvasti laskevalla rajahyödyllä ja nousevalla drawdown-riskillä.
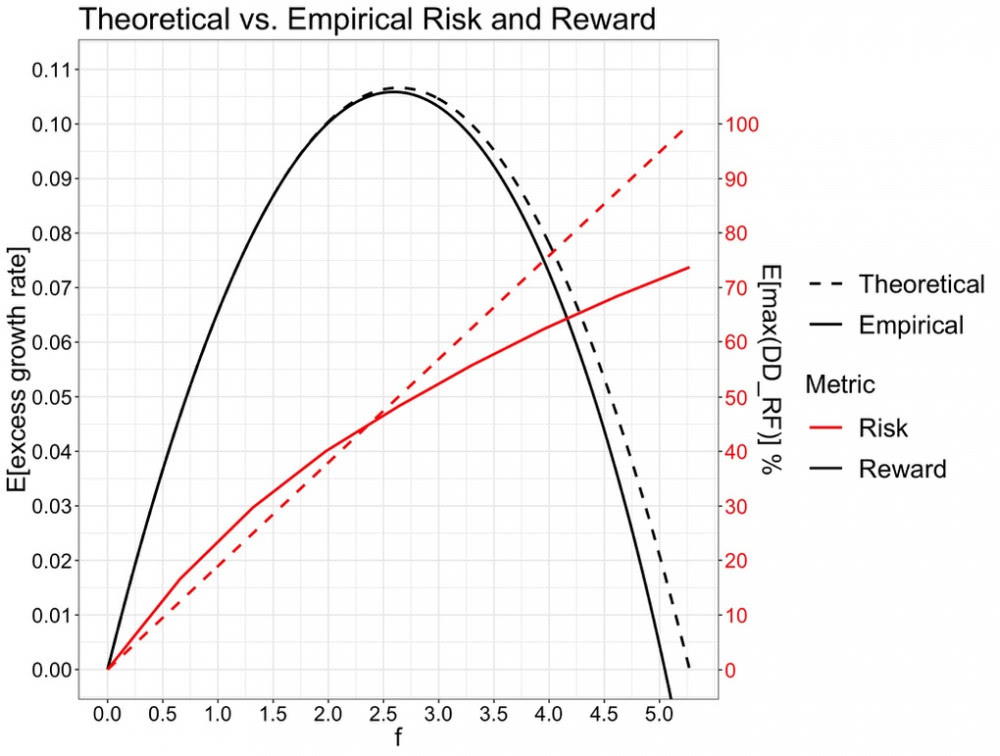
Riskikorjattu tuotto:
Ylläolevassa kuvassa meillä on riski ja tuotto. Voimme siis halutessamme laskea myös riskikorjatun tuoton näillä metriikoilla. Maksimi drawdown korjattu geometrinen riskittömän koron ylittävä tuotto-odotus on (c:n ja f:n funktiona):
E(G)/E[max(DD_RF)] = 2SR^2 – cSR^2 = 2SR^2 – fsSR
Kaavan antama arvo riskikorjatulle tuotolle ei ole niin oleellinen, mutta mielenkiintoista on käyrän muoto: laskeva suora, joka saavuttaa nollan kun c = 2 eli kun geometrinen riskittömän koron ylittävä tuotto-odotus menee nollaan. Näemme myös, että tämäkin riskikorjattu metriikka maksimoituu (valitulla sijoitusasteella), kun Sharpe ratio maksimoidaan.
Alla olevassa kuvassa näemme kaikki kolme teoreettista metriikkaa vielä kukin normalisoituna omalla maksimiarvollaan. Normalisoinnin ansiosta on helpompi nähdä miten esimerkiksi ”half Kelly” (c = ½) antaa 3/4 ”full Kelly” (c = 1) tuotto-odotuksesta samalla kun maksimi drawdown-riski on puolet. Kuvasta nähdään, että riskikorjattu tuotto on maksimissaan, kun sijoitusaste lähestyy nollaa ja laskee lineaarisesti, kun sijoitusaste kasvaa. Geometrisilla (toisin kuin aritmeettisilla) riskikorjatuilla metriikoilla riskikorjattu tuotto pienenee sijoitusasteen funktiona. Sama tapahtuu esimerkiksi geometrisella Sharpe ratiolla (jossa aritmeettinen excess return on korvattu geometrisella excess returnilla). Sijoitusasteen kasvattaminen ja lopulta vivuttaminen siis heikentävät ajan yli korkoa korolle -ilmiöstä hyötymään pyrkivän sijoittajan riskikorjattua tuottoa. Kuvassa näkyvä paraabelin vasen puolisko (välillä 0 < c <= 1) on geometrinen efficient frontier, joka tarjoaa maksimaalisen geometrisen tuotto-odotuksen riskiyksikköä kohti. Riski voidaan määrittää portfolion kokonaiskeskihajontana fs, Kelly fraktiona c tai vaikka maksimi drawdown-riskinä E[max(DD_RF)].
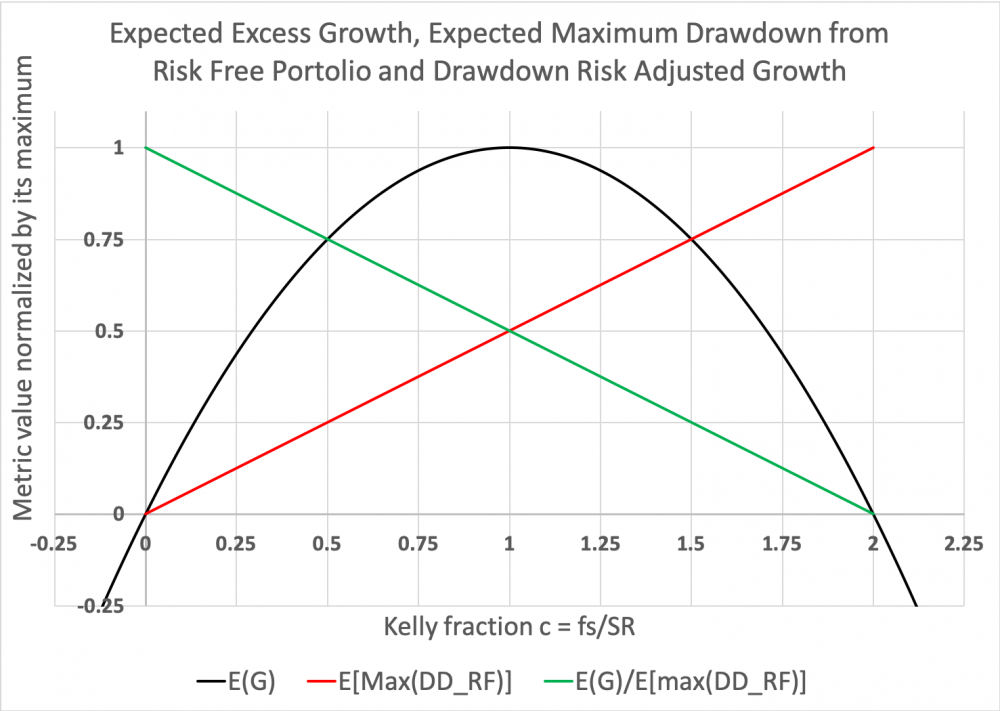
Yhteenveto:
- Tarkastelin riskinä drawdown-riskiä eli sijoitusmatkan kuoppaisuutta ja erityisesti maksimikuopan odotettua syvyyttä sijoitushorisontin lopussa realisoituvan tappion tai tuoton epävarmuuden sijaan.
- Drawdown-riski on tässä tapauksessa odotusarvo portfolion maksimi drawdownille riskittömän portfolion arvosta jollakin ajan hetkellä tästä ajanhetkestä eteenpäin.
- Nollakorkoympäristössä tämä on sama kuin odotusarvo portfolion maksimi drawdownille nykyarvosta jollakin ajan hetkellä tästä ajanhetkestä eteenpäin.
- Teoreettinen Drawdown-riski on yksinkertaisesti portfolion Kelly fraktio jaettuna kahdella (c/2) eli portfolion kokonaisvolatiliteetti (fs) jaettuna kahdella Sharpe ratiolla (2SR).
- Teoreettinen kaava toimii sekä simulaatiossa että empiirisesti. Noin 10 vuoden periodi näyttää riittävän pitkältä empiirisessä datassa, jotta kaavan ennustukset ovat kohtuullisen tarkkoja sijoittajalle relevanteilla sijoitusasteilla.
- Empiiristen tuottojen aikasarjan korrelaatiot kasvattavat drawdown-riskiä verrattuna i.i.d perustaiseen teoriaan.
- Drawdown-riski (valitulla sijoitusasteella) minimoidaan ensisijaisesti maksimoimalla Sharpe ratio. Onnistuessaan time series momentum strategia osana portfoliota voi myös potentiaalisesti pienentää drawdown-riskiä.
- Drawdown-riskiä voi alentaa myös sijoitusastetta laskemalla, joskin samalla tulee alennettua myös tuotto-odotusta. Riittävän suurella (kun c --> 2) sijoitusasteella maksimi drawdownin odotusarvo lähestyy 100% samalla kun geometrinen tuotto-odotus lähestyy riskittömän koron tuottoa.
